No fundo, toda inteligência artificial moderna tenta apenas imitar o que você faz sem pensar.
Quando você decide se vai atravessar a rua ou se aquele e-mail vai pra caixa de spam, seu cérebro está processando sinais, pesando evidências e tomando uma decisão simples: sim ou não.
Nas redes neurais artificiais, tudo começou como uma tentativa de replicar esse comportamento em um modelo matemático, gerando o que conhecemos como Perceptron, que é, até hoje, uma das ideias mais elegantes da computação.
Origem
A história da aprendizagem de máquina começa não com supercomputadores, mas com papel e caneta, lá na década de 40. A seguir, podemos ver uma breve timeline dessa história:
- 1943 - Neurônio Artificial (McCulloch & Pitts): o ponto de partida foi um modelo matemático do neurônio biológico. Era uma estrutura puramente lógica: se as entradas somassem um valor X, o neurônio disparava. O problema? Ele não aprendia - todas as regras precisam ser definidas manualmente.
- 1958 - Perceptron (Frank Rosenblatt): aqui foi introduzido o conceito de pesos. Pela primeira vez, o algoritmo podia ajustar sua própria importância para cada entrada com base em erros. Se ele errasse a resposta, ele mexia nos pesos até acertar. Foi um dos primeiros modelos com capacidade real de aprendizado.
- 1969 - O Inverno da IA (Marvin Minsky & Seymour Papert): um livro foi publicado provando que o Perceptron original não conseguia resolver problemas simples como o XOR (ou-exclusivo). Isso jogou um balde de água fria na área, contribuindo significativamente para o ceticismo que levou ao chamado “Inverno da IA”, onde o financiamento e o interesse sumiram por anos.
O que não foi previsto é que o problema não era a ideia de redes neurais, mas sim a limitação de usar apenas uma camada. Mas isso é assunto para outro post.
Fundamentos Biológicos
Para entender o Perceptron, precisamos olhar para sua origem: o nosso próprio sistema nervoso. Um neurônio biológico é basicamente um processador de sinais químicos e elétricos com quatro partes principais:
- Dendritos: são os “cabos de entrada”, que recebem os sinais de outros neurônios.
- Soma (corpo celular): é onde o “processamento” acontece. Ele soma todos os sinais que chegam e, se a carga elétrica total ultrapassar um certo limiar, o neurônio decide disparar.
- Axônio: é o “cabo de saída”, que conduz o sinal para o próximo neurônio.
- Sinapse: é a conexão entre neurônios. Na fenda sináptica, substâncias químicas aumentam ou diminuem a força do sinal. Nas redes neurais, chamamos isso de pesos.
Simplificando, é o conceito de tudo ou nada: ou o neurônio atinge o potencial necessário e dispara, ou ele fica quieto. Não existe meio disparo.
A Ponte para o Artificial
E como transformamos isso em código? É mais simples do que parece:
- As Entradas são os dados (ex: o tamanho de uma casa ou o preço de uma ação).
- Os Pesos dizem qual entrada é a mais importante.
- O Somatório acontece no “corpo” do nosso neurônio artificial.
- A Função de Ativação (o limiar) decide se o resultado final é 0 ou 1.
Essa abstração nos permitiu parar de tentar entender a biologia molecular e passar a usar álgebra linear para ensinar máquinas.
O Neurônio Artificial
Se o neurônio biológico é um processador de sinais, o neurônio artificial é uma função matemática, que recebe uma lista de números, faz um cálculo e cospe outro número.
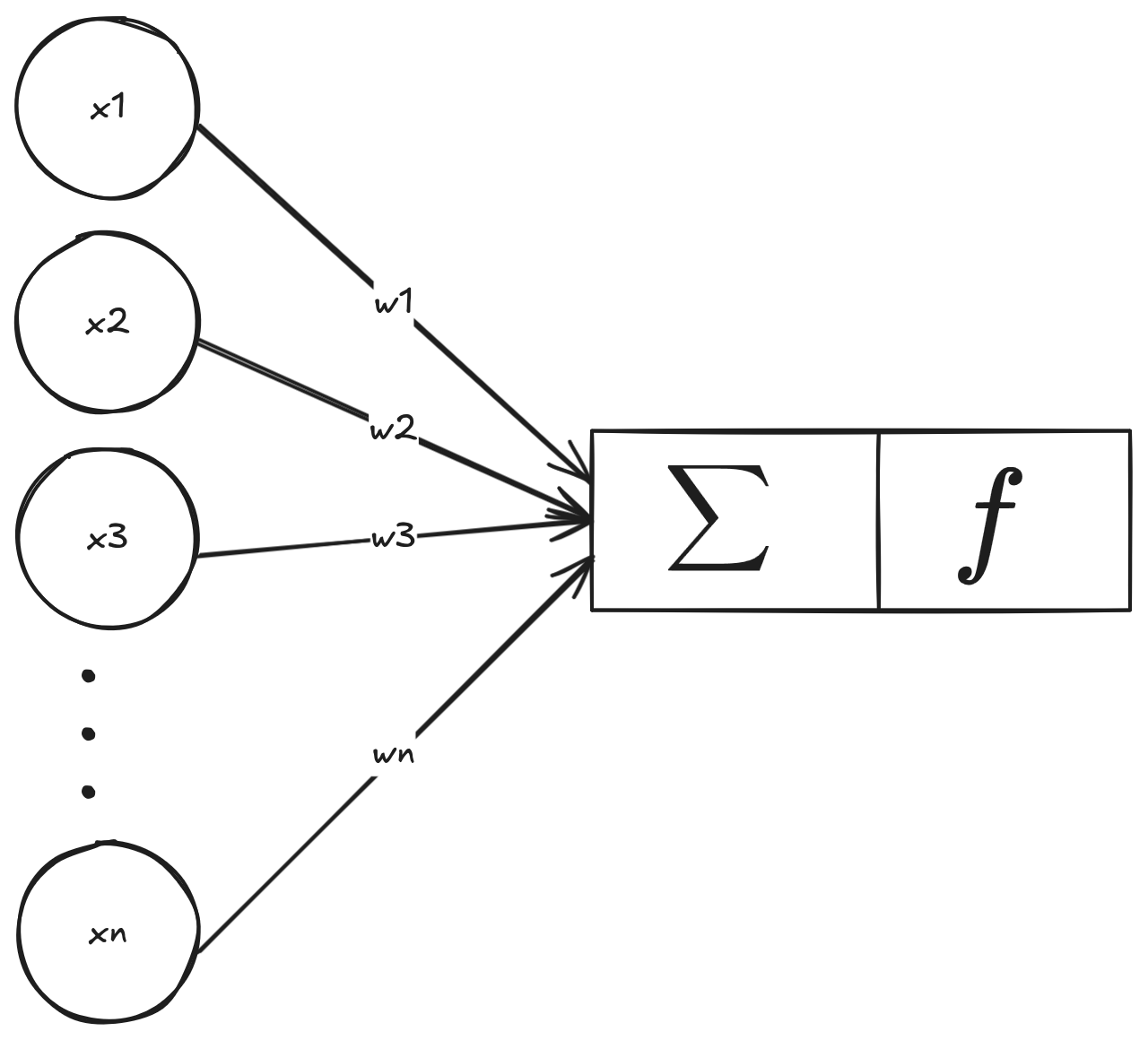
Onde x1..xn são as entradas, e w1..wn são os pesos.
Entradas e Pesos
Cada informação que entra no neurônio ($x$) tem um peso ($w$) associado:
- Um peso positivo funciona como uma sinapse excitadora (amplifica o sinal).
- Um peso negativo funciona como uma sinapse inibidora (reduz ou bloqueia o sinal).
O “conhecimento” da rede neural não está em um banco de dados, mas sim guardado nesses pesos. Ou seja, quando dizemos que uma rede neural está “aprendendo”, estamos dizendo que ela está ajustando esses números até que a saída faça sentido.
A Função Soma e o Dot Product
O primeiro passo do neurônio é somar tudo o que chegou, de forma ponderada. Multiplicamos cada entrada pelo seu respectivo peso e somamos os resultados: $$ Soma = (x_1 \cdot w_1) + (x_2 \cdot w_2) + \dots + (x_n \cdot w_n) $$ Em programação, fazer esse loop manualmente para milhares de entradas seria lento. Para resolver isso, podemos usar o Dot Product (produto escalar). Em vez de iterar, tratamos as entradas e os pesos como dois vetores e deixamos que a álgebra linear faça o trabalho de uma vez só.
Em Python, usando a biblioteca Numpy, isso é feito com o método .dot(), que é otimizado em C e muito mais rápido que qualquer loop for em nativo.
Função de Ativação
Depois de somar tudo, precisamos decidir se o neurônio dispara ou não. Para isso, usamos uma Função de Ativação.
No caso do Perceptron clássico, usamos a Step Function (Função Degrau). Se a soma for maior que um limiar (threshold), ela retorna 1 (disparou). Se não, retorna 0.
Prática
Vamos ver como isso tudo funciona na prática:
import numpy as np
# Características de entrada
inputs = np.array([1, 7, 5])
# Pesos do neurônio
weights = np.array([0.8, 0.1, 0.0])
THRESHOLD = 0.1
def weighted_sum(inputs, weights):
"""Calcula a soma ponderada das entradas."""
return inputs.dot(weights)
def step_activation(value, threshold):
"""Função de ativação degrau."""
return int(value >= threshold)
if __name__ == '__main__':
weighted_sum_result = weighted_sum(inputs, weights)
print(f"Resultado da soma: {weighted_sum_result}")
output = step_activation(weighted_sum_result, THRESHOLD)
print(f"O neurônio disparou? {output}")
Com apenas algumas linhas, replicamos o comportamento básico de uma célula nervosa. Tá, mas aí você me pergunta: como esses pesos são definidos? Como o algoritmo sabe que deve ser 0.8 e não 0.2?
Isso nos leva ao conceito de Aprendizagem de Máquina, que é o coração do treinamento de redes neurais.
Tipos de Aprendizagem
Antes de ajustarmos os pesos, precisamos entender como a máquina aprende. Existem três caminhos principais:
- Aprendizagem não supervisionada: o algoritmo tenta encontrar padrões sozinho em dados sem rótulos (ex: agrupar clientes por comportamento de compra).
- Aprendizagem por reforço: baseada em tentativa e erro. O modelo recebe “recompensas” por acertos e “punições” por erros (ex: uma IA aprendendo a jogar um determinado jogo).
- Aprendizagem supervisionada: fornecemos os dados de entrada e a resposta correta. O objetivo do modelo é aprender a mapear um para o outro.
Esse post foca na aprendizagem supervisionada.
Exemplo: Peixe vs Baleia
Imagine que queremos classificar peixes e baleias. Nossas entradas (características) poderiam ser o tamanho do animal e se ele respira fora d’água.
Se passarmos que o animal é gigante, e tem pulmão, dizemos ao neurônio: “Para esses valores, a resposta correta é 1 (Baleia)”.
Se ele calcular 1 (Peixe), ele sabe que errou e precisa se ajustar.
Ajuste de Pesos
No contexto de uma rede neural, aprender nada mais é do que minimizar o erro. Esse processo utiliza uma técnica clássica chamada Regra de Aprendizagem do Perceptron. O ciclo segue uma lógica simples:
- O neurônio faz um cálculo (com pesos iniciais aleatórios ou zerados).
- Calculamos o erro: $erro = respostaCorreta - respostaCalculada$.
- Ajustamos os pesos para que, na próxima vez, o erro seja menor.
A Fórmula de Atualização
A Regra de Aprendizagem do Perceptron utiliza a seguinte fórmula para atualizar cada peso:
$$peso_{novo} = peso_{atual} + (\eta \cdot entrada \cdot erro)$$
Onde $\eta$ representa a Taxa de Aprendizagem, que controla o “tamanho do passo” do ajuste. Se for muito alta, o aprendizado é instável. Se for muito baixa, o neurônio demora demais para aprender. Geralmente usam-se valores como 0.1 ou 0.2.
Nota: em modelos mais robustos, existe um parâmetro extra chamado Bias, que funciona como um peso para uma entrada que é sempre 1, permitindo que o neurônio desloque sua curva de decisão. Para facilitar, focaremos apenas nos pesos.
Caso Prático 1: Operador AND
Podemos ver isso em funcionamento com uma tabela verdade do operador lógico AND. O objetivo é que o neurônio só dispare (1) quando ambas as entradas forem 1.
| $x_1$ | $x_2$ | Classe (Correto) |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
Treinamento
Se começarmos com pesos valendo 0 e um limiar de 1, o neurônio vai errar o último caso ($1, 1 \to 1$), pois a soma será $0$.
- Erro detectado: 1 (correto) - 0 (calculado) = 1
- Ajuste: usando uma taxa de aprendizagem de 0.1, os pesos vão subindo a cada rodada (ou melhor, a cada época).
- Convergência: após algumas épocas, os pesos chegarão a 0.5. Agora, quando $x_1=1$ e $x_2=1$, a soma será $0.5+0.5=1.0$. O neurônio atinge o limiar e finalmente acerta!
O mais interessante é que não programamos a regra do AND. Nós apenas demos os exemplos e o neurônio “descobriu” os pesos necessários para satisfazer a lógica.
Implementando o Ciclo de Treinamento
Transformando toda essa teoria em um script Python, o ponto chave é o laço while: ele representa o esforço da rede em repetir o processo (as Épocas) até que o erro total seja zero, ou seja, até que ela acerte todas as combinações da tabela AND.
import numpy as np
LEARNING_RATE = 0.1
THRESHOLD = 1.0
# Tabela verdade da função lógica AND.
inputs = np.array([
[0, 0],
[0, 1],
[1, 0],
[1, 1]
])
outputs = np.array([0, 0, 0, 1])
# Pesos iniciais do perceptron.
weights = np.array([0.0, 0.0])
def step_activation(value):
# Função de ativação: se atingir o limiar, retorna 1.
return int(value >= THRESHOLD)
def predict(sample):
# Dot Product seguido da Ativação.
weighted_sum = sample.dot(weights)
return step_activation(weighted_sum)
def train():
total_error = 1 # Começamos com erro para entrar no loop
# O loop continua até que a rede acerte 100% das amostras (erro zero)
while total_error != 0:
total_error = 0
print(f"Inicio da época - pesos: {weights}")
for sample, expected_output in zip(inputs, outputs):
predicted_output = predict(sample)
error = expected_output - predicted_output
# Acumula o erro absoluto para controle do loop
total_error += abs(error)
# Regra de aprendizado do perceptron:
# Atualiza os pesos de forma proporcional ao erro e à taxa de aprendizado
weights[:] += LEARNING_RATE * sample * error
print(f"Fim da época - pesos: {weights}")
print(f"Total de erros: {total_error}\n")
if __name__ == '__main__':
train()
print("Rede neural treinada")
# --- Demonstração de funcionamento ---
print("--- Testando a rede treinada ---")
for sample in inputs:
result = predict(sample)
print(f"Entrada: {sample} -> Saída prevista: {result}")
Ao executar esse código, vemos os pesos “escalando” de $0.0$ até $0.5$. Na última etapa, a rede realiza o teste final e podemos ver que as saídas previstas são identicas à tabela verdade do operador AND, sinalizando que o neurônio agora “entende” o operador lógico.
Caso Prático 2: Operador OR
Diferente do AND, onde ambas as entradas precisam ser 1, no operador OR basta que uma das entradas seja 1 para o neurônio disparar.
| x1 | x2 | Classe (Correto) |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
O código para treinar o OR é idêntico ao do AND, bastando alterar o array de outputs:
# Tabela verdade da função lógica OR.
outputs = np.array([0, 1, 1, 1])
Com as mesmas configurações, a rede convergirá para pesos que satisfaçam a lógica OR.
Caso Prático 3: Peixe vs Baleia (Generalização)
Diferente do operador AND, que é uma regra lógica exata, na vida real os dados são mais variados. Para exemplificar isso, vamos treinar o Perceptron para diferenciar um Peixe de uma Baleia usando duas características: o Tamanho (0 a 1) e se ele possui Pulmão (1) ou guelras (0).
import numpy as np
LEARNING_RATE = 0.1
THRESHOLD = 0.5
# Dataset: [Tamanho, Respira por Pulmão (0=Não, 1=Sim)]
# Rótulos: 0 = Peixe, 1 = Baleia
inputs = np.array([
[0.1, 0], # Peixe pequeno
[0.2, 0], # Peixe médio
[0.8, 1], # Baleia grande
[0.9, 1] # Baleia gigante
])
outputs = np.array([0, 0, 1, 1])
weights = np.array([0.0, 0.0])
def step_activation(value):
return int(value >= THRESHOLD)
def predict(sample):
return step_activation(sample.dot(weights))
def train():
total_error = 1
while total_error != 0:
total_error = 0
for sample, expected in zip(inputs, outputs):
error = expected - predict(sample)
total_error += abs(error)
weights[:] += LEARNING_RATE * sample * error
if __name__ == '__main__':
train()
# Testando com um Golfinho (Tamanho médio, mas tem Pulmão)
golfinho = np.array([0.5, 1])
res = predict(golfinho)
print(f"Resultado para o Golfinho: {'Baleia/Mamífero' if res == 1 else 'Peixe'}")
O mistério do Golfinho
Ao rodar esse script, notamos que o Golfinho é classificado como Peixe. Podemos tirar algumas conclusões:
- O algoritmo é “preguiçoso”: o Perceptron para de treinar assim que encontra qualquer linha que separe os dados. Se ele decidiu que “ser gigante” é o critério principal, ele vai ignorar o pulmão para animais de tamanho médio.
- Falta de diversidade: nós não demos exemplos de animais médios com pulmão. Para o neurônio, baleias são apenas “coisas gigantes”.
- Bias: sem esse parâmetro (que mencionamos na nota anterior), a rede neural tem menos flexibilidade para ajustar sua linha de decisão, o que pode levar a erros de generalização como este.
Para corrigir esses problemas, precisaríamos de um conjunto de dados mais rico ou de uma arquitetura mais complexa.
Caso Prático 4: Operador XOR
Lá em cima, quando falamos sobre a Origem, mencionei que o Perceptron causou um “Inverno da IA”, e o grande culpado foi o operador XOR (OU Exclusivo).
Diferente do OR, o XOR só dispara se exatamente uma das entradas for 1. Se ambas forem 1, a saída deve ser 0.
| x1 | x2 | Classe (XOR) |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Basta tentar substituir o array de outputs pelo seguinte:
# Tabela verdade do XOR - O Perceptron falhará aqui!
outputs = np.array([0, 1, 1, 0])
Se você tentar treinar a rede neural com esses outputs, verá que o loop while entrará em um loop infinito, e o erro nunca chegará a zero.
Por que a falha?
O Perceptron é um classificador linear. Isso significa que ele tenta traçar uma linha reta para separar os zeros dos uns.
No AND e no OR, você consegue desenhar essa linha. No XOR, os pontos estão distribuidos de tal forma que é matematicamente impossível separá-los com uma única linha reta.
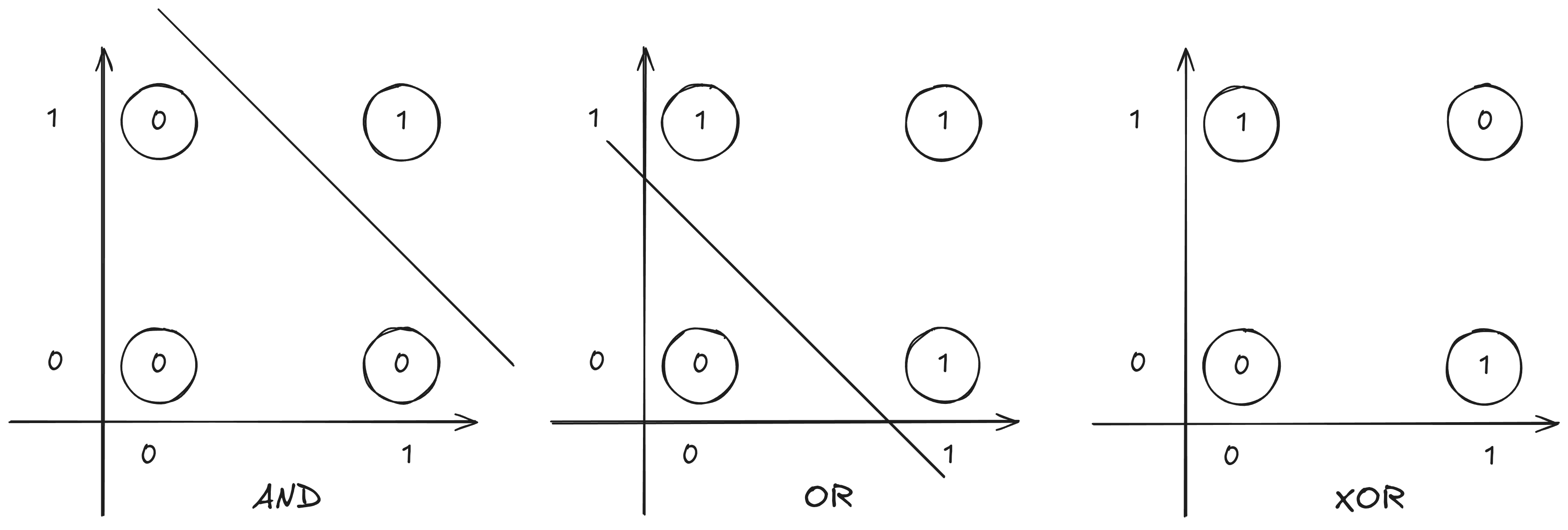
No caso do XOR, nenhuma linha reta consegue separar as classes corretamente.
Este foi o limite que paralisou a área por anos. A solução só viria mais tarde com a adição de camadas ocultas, criando o que chamamos de Redes Neurais Multicamadas, capazes de criar curvas e formas complexas para separar qualquer tipo de dado.
Conclusão
O que Frank Rosenblatt construiu em 1958 não foi apenas um algoritmo, mas uma ponte. É fascinante (e assustador) pensar que, quase 70 anos depois, essas multiplicações de matrizes e ajustes de pesos continuam no núcleo das IAs mais avançadas do mundo.
O Perceptron tem seus limites: é preguiçoso e precisa de dados bem preparados para não confundir golfinhos com peixes. Mas esses limites foram o pontapé para a criação das Redes Neurais Multicamadas e do Deep Learning. O problema do XOR fez a ciência parar de olhar para os neurônios isolados e começar a olhar para a conexão.
A inteligência artificial moderna não é apenas um Perceptron em grande escala. Técnicas como camadas ocultas resolvem a não-linearidade, bias traz flexibilidade, e funções de ativação modernas e algoritmos como Backpropagation permitem que o aprendizado flua por redes neurais profundas. No final das contas, a IA atual pode até ser assustadoramente complexa, mas a mecânica fundamental que dita como ela aprende ainda começou ali, naquele primeiro neurônio artificial, lá na década de 50.
Obrigado por ler até aqui, e nos vemos no próximo post!